Índices Utilizados e Inactivos en SQL Server
Guardada en SQL Server, publicada en - Página vista 11919 veces
Introducción:
Este manual ha sido extraído de una fuente que actualmente no está operativa, imagino que la página inicial está caída de manera indeterminada, porque ya hace más de un mes que no responde la Web donde estaba albergado, así que no citaré la fuente de origen para no tener enlaces rotos. Solo decir que el artículo fue creado originalmente en sql-server-performance.com
Creo que este manual era tan bueno que es una lástima que se pierda en la red, así que para que todo el mundo pueda seguir disfrutando de él lo reproducimos en nuestra sección de SQL Server.
Coloco aquí la introducción original del artículo:
En un artículo anterior describí una metodología para encontrar los índices no activos en una base de datos.
Aquellos que lo hayan leído, habrán encontrado que el proceso de detección de tales índices es lento y conlleva mucho trabajo.
Se me ocurrió, entonces, pensar en forma inversa. Es decir, si podemos encontrar cuáles son los índices realmente utilizados, entonces podremos inferir cuáles no lo son.
Me he basado en un artículo de Tom Pullen (disponible en este Forum) sobre los objetos que se encuentran en el Cache de memoria en cada instante. He modificado algunos parámetros y variables de lo escrito por Tom para obtener los objetos (en este caso índices) que se encuentran en el buffer permanentemente.
El proceso consiste en almacenar en una tabla los objetos que se encuentran en el Buffer Cache para luego compararlo con todos los índices que contenga esa base de datos.
En mi caso, optimizo distintas bases de datos de distintos clientes agregándole los índices necesarios para optimizar cada una de ellas. Pero a lo largo del tiempo puede ocurrir que alguno de esos índices estén obsoletos y requieran ser removidos.
Es importante la aclaración anterior, dado que los índices originales que fueron creados por los programadores de esas bases de datos no son modificados ni eliminados en forma alguna. Al tratarse de Software de Terceros, no es mi función modificar ni el código ni los índices creados por ellos. Repito que me refiero solamente a los creados por mí en el proceso de optimización.
Para aquellos DBA que están en contacto con los programadores, les servirá para discutir con ellos la necesidad de mantenerlos o no.
Paso 1: Creación de una base de datos para administrar todas las tablas y procedimientos.
A los efectos de mantenimiento es conveniente crear una base de datos independiente para administrar todo el proceso.
A los fines ilustrativos supongamos que la llamamos: AdminCache
Paso 2: Creación de la tabla para almacenar el contenido de Buffer Cache.
CREATE TABLE [dbo].[MemusageRecord] (
[dbid] [int] NOT NULL ,
[objectid] [int] NOT NULL ,
[indexid] [int] NOT NULL ,
[Buffers] [int] NOT NULL ,
[Dirty] [int] NOT NULL ,
[InsertDate] [datetime] NOT NULL
) ON [PRIMARY]
GO
CREATE CLUSTERED INDEX [mur001] ON [dbo].[memusagerecord]([InsertDate]) ON [PRIMARY]
GO
ALTER TABLE [dbo].[memusagerecord] ADD
CONSTRAINT [DF_getdate_insertdate] DEFAULT (getdate()) FOR [InsertDate]
Paso 3: Creación de un procedimiento para cargar la tabla
CREATE PROCEDURE prMemusageRecord
AS
CREATE TABLE #memusagerecord
(
dbid int,
objectid int,
indexid int,
Buffers int,
Dirty int,
)
INSERT INTO #memusagerecord EXEC('DBCC MEMUSAGE (IDS, ' + '200' + ')')
INSERT INTO MemusageRecord
(dbid, objectid, indexid, Buffers, Dirty)
SELECT dbid, objectid, indexid, Buffers, Dirty
FROM #memusagerecord
DROP TABLE #memusagerecord
GO
La función DBCC MEMUSAGE es la que permite conocer los objetos presentes en la Cache Buffer en ese momento. El número 200 es la cantidad de objetos que quiero obtener. Este número es arbitrario y puede ser ajustado de acuerdo a cada instalación en particular.
Paso 4: Creación de un procedimiento para obtener la salida de los objetos almacenados en la tabla creada en Paso 1 y cargada en Paso 2.
CREATE PROCEDURE prCheckRecentCache @dbname SYSNAME
AS
DECLARE @sql VARCHAR(8000)
SELECT @sql =
'SELECT so.name as ''Object'', x.name,
CASE m.indexid
WHEN 0 THEN ''Data''
WHEN 1 THEN ''Clustered Index''
ELSE ''Nonclustered Index ID: ''+ CONVERT(VARCHAR, m.indexid)
END AS ''Cache Data Type'',
CONVERT(DECIMAL(9,2),8*m.Buffers/1024.00) AS ''MB Cached'', m.InsertDate, db_name(dbid) AS ''Database''
FROM
AdminLuisNueva..MemusageRecord m
JOIN ' + @dbname + '..sysobjects so
ON m.objectid = so.id
JOIN ' + @dbname + '..sysindexes x
on so.id = x.id
WHERE x.indid = m.indexid
AND m.dbid=db_id('''+@dbname+''')
ORDER BY ''MB cached'' DESC '
EXECUTE (@sql)
GO
Como se puede observar en el código la variable es el nombre de la base de datos.
En el caso de varias bases de datos, sería recomendable tener una tabla y procedimientos separados para cada base.
Paso 5: Creación de un Trabajo que ejecute el procedimiento prMemusageRecord con periodicidad acorde a cada instalación.
La creación de este Trabajo y su periodicidad, dependerá de cada instalación. Como sugerencia podría ejecutarse durante los días de trabajo, en los horarios de trabajo y cada 5 minutos.
Esto quiere decir que a la tabla se le insertarán 200 registros cada 5 minutos.
Dejo para el lector la creación de cada trabajo.
Paso 6: Creación de un Trabajo que ejecute el procedimiento prCheckRecentCache en los mismos días y horarios del anterior pero cada 15 minutos.
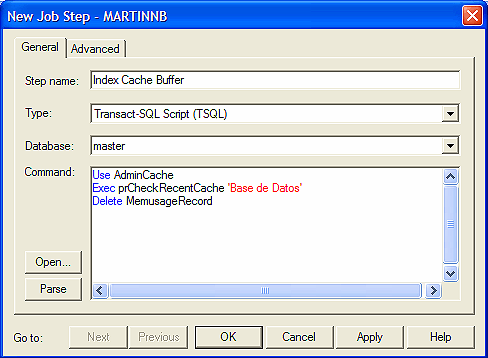
El paso del trabajo debería quedar como sigue:
Use AdminCache
Exec prCheckRecentCache 'Base de Datos'
Delete MemusageRecord
La tercera sentencia es a los efectos de eliminar los registros de la tabla y no crezca indefinidamente. Dado que la segunda sentencia generará un archivo plano con el salida del contenido de la tabla, no es necesario que permanezcan almacenados los datos que fueron procesados.
Para generar el archivo plano, veamos gráficamente como se obtiene este paso:
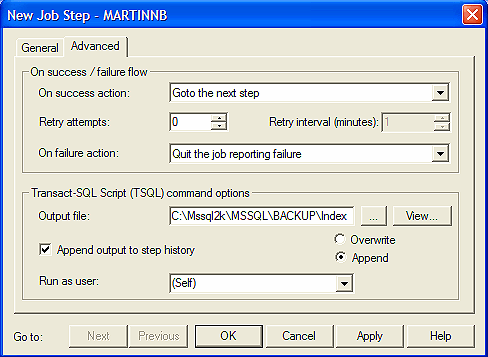
Como vemos el Trabajo se ejecutará (digamos cada 15 minutos) y su resultado será agregado al archivo definido en «Output file:».
Una vez que los Trabajos funcionan adecuadamente, debemos definir cuándo realizaremos el proceso de analizar el resultado del archivo plano.
Esta tarea también depende de cada instalación en particular. Tenemos que tener en cuenta que en algunas Empresas existen procesos que se ejecutan una o dos veces en el mes. Por lo tanto el tiempo mínimo sugerido sería de un mes.
Por supuesto a los fines de probar todo el proceso, se puede realizar en cualquier momento dado que tenemos resultados almacenados en el archivo de texto luego de los 15 minutos de agenda-do el trabajo.
Paso 7: Generación de una tabla, utilizando el DTS, para almacenar los resultados del archivo de texto.
Para esto usamos en Administrador Corporativo, abrimos las bases de datos, nos posicionamos en la base creada por nosotros (AdminCache), tablas, botón derecho del mouse, todas las tareas, importar datos. (En el ejemplo la base se llama AdminLuisNueva).
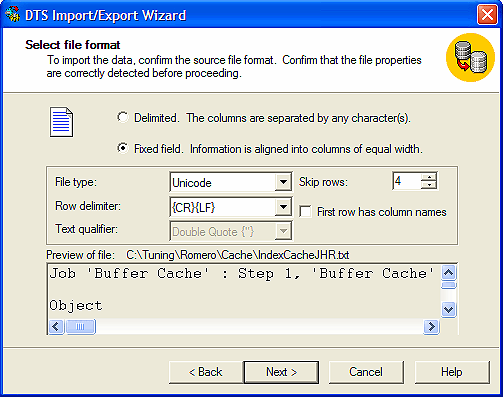
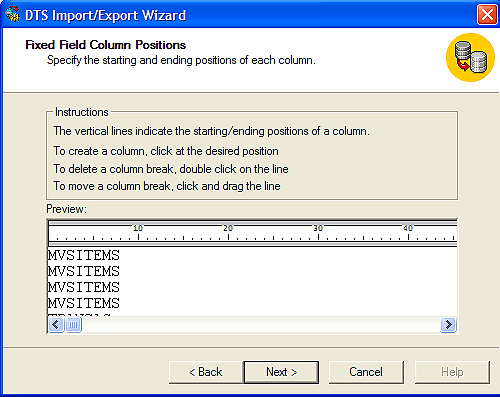
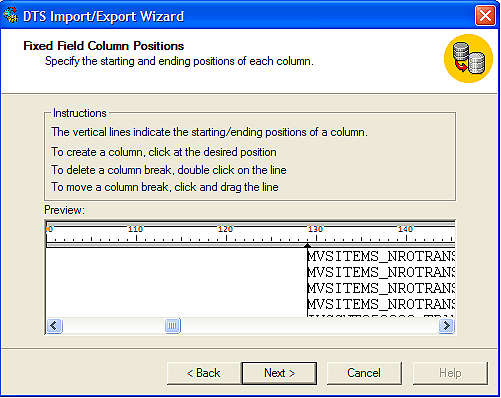
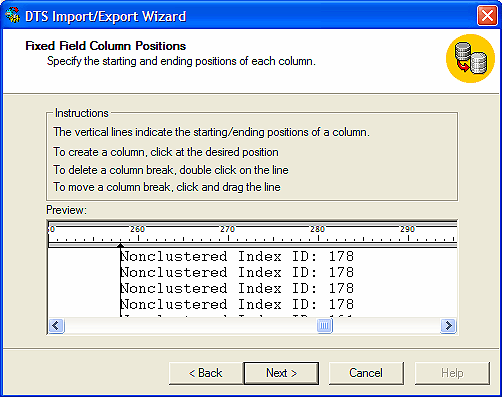
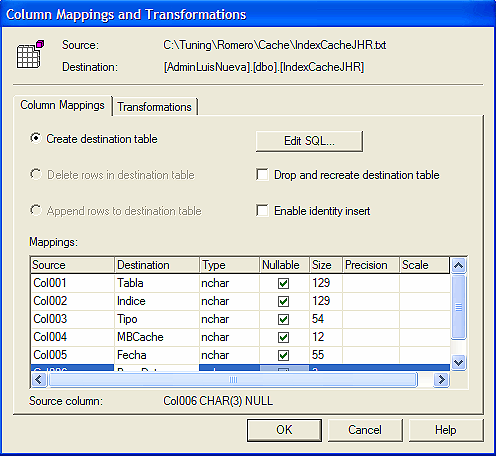
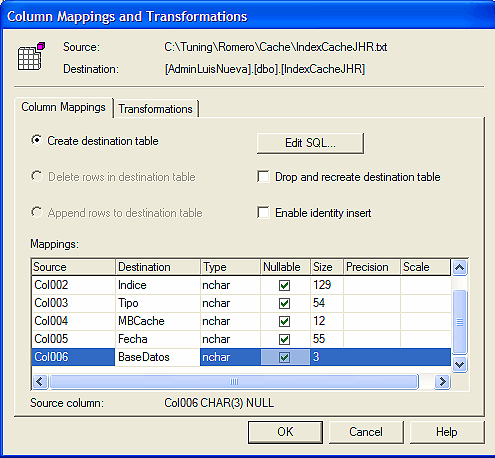
Por último creamos el DTS,
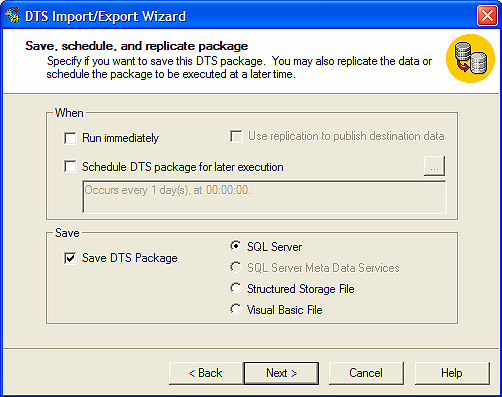
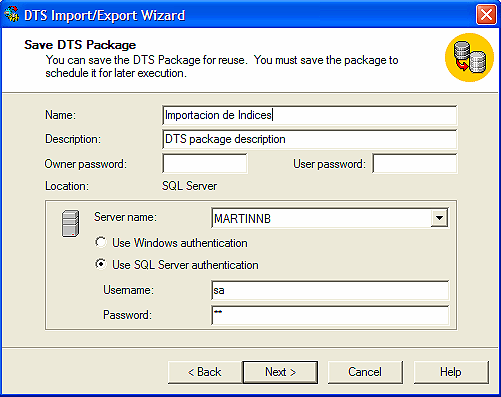
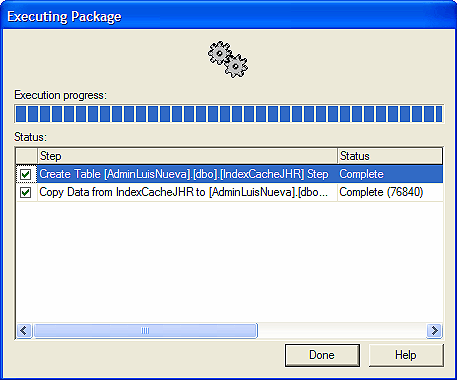
Como vemos se han importado 76840 registros que es el producto de varios días de recolección de datos almacenados en el archivo plano.
Veamos uno registros ejecutando un select sobre la tabla creada.
El nombre de la tabla creada es igual al archivo plano, lo cual es arbitrario.
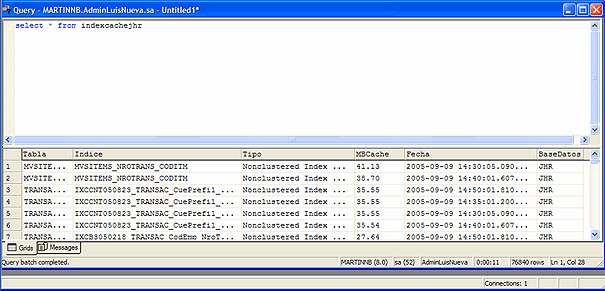
Con buena vista se puede observar que existen índices repetidos, lo cual es lógico dado que cada 15 minutos se agregan registros al archivo plano y puede no haber cambiado nada en contenido de Cache Buffer.
La idea de crear el DTS es a los fines de ejecutarlo cada vez que sea necesario sin necesidad de crearlo nuevamente.
Es aconsejable que, una vez finalizado todo el método descrito, borrar la tabla generada para que al ejecutar el DTS dentro de, digamos 2 meses, tener información nueva y no vieja.
Paso 8: Creación de una tabla con todos los índices de la base de datos.
En el siguiente SQL, creamos una tabla en la base AdminCache (en el ejemplo AdminLuisNueva) y la cargamos con todos los índices de la base de datos que estamos estudiando. En este caso su nombre es JHR.
Use Adminluisnueva
if exists (select * from dbo.sysobjects where id = object_id(N'[IndicesJHR]') and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [IndicesJHR]
GO
Create Table IndicesJHR (Filas int, Tabla varchar(50), IndicesActuales varchar(50))
Use JHR
go
insert into AdminLuisNueva.dbo.IndicesJHR
select si.rows as 'filas', SO.Name as Tabla, SI.name as 'Indices'
from sysobjects as SO
join sysindexes as SI
on SO.Id = SI.id
Tenemos ahora dos tablas. Una IndicesJHR contiene todos los índices de la base JHR. La otra tabla IndexCacheJHR contiene todos los índices que estuvieron en el Cache Buffer durante el tiempo estudiado, por ejemplo 1 mes.
Paso 9: Análisis de los índices no activos.
Con estas dos tablas podemos saber cuáles de los índices no han sido utilizados en ese período y son candidatos a ser eliminados.
Para esto basta ejecutar la siguiente consulta:
select * from IndicesJHR where IndicesActuales not in ( select Indice from indexcacheJHR)order by Indicesactuales
En el caso real aquí explicado, el resultado mostró 23 índices con posibilidad de ser eliminados por no estar activos.
Conclusiones
Esta metodología presenta dos posibilidades. La primera de ellas es saber cuáles de todos los índices de la base de datos se encuentran en el Cache Buffer y, por lo tanto, son los más usados por SQL Server. La segunda es inferir como consecuencia, cuáles de los índices son candidatos a ser eliminados.

Publicado por Labelgrup
Creador de páginas web, con experiencia en diferentes campos en el mundo del desarrollo web.